Как устроена видеокарта?
Видеокарта работает на программном (потоки, блоки и массивы данных) и аппаратном (вычислительные блоки и память) уровнях:
Видеокарты с физической точки зрения представляют собой сложные электронные устройства, собранные на многослойной печатной плате с внутренними проводящими слоями, которая служит основой для установки электронных элементов, обеспечивающих необходимый функционал.
Основными функциями видеокарт являются вывод изображения на монитор и проведение сложных параллельных вычислений.
Для этого в составе видеокарты на физическом уровне имеются следующие основные узлы:
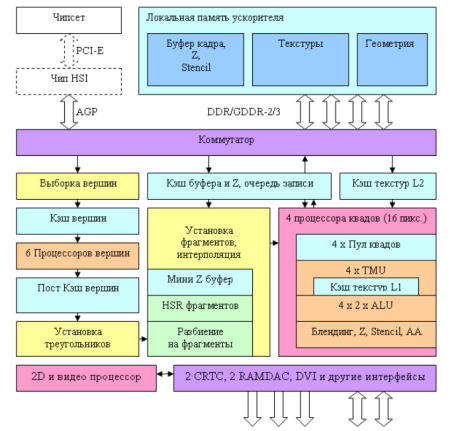
- графический процессор (GPU, сокращение от англ. GraphicProcessorUnit), предназначен для проведения сложных многопотоковых вычислений для последующего вывода изображения. Внутри GPU есть блоки, ответственные за обработку 2D (прорисовка примитивов, перенос блоков, масштабирование, работа с окнами, преобразование цвета) и 3D-графики (просчет проекции виртуального динамического трехмерного объекта, зрительные эффекты, трассировка лучей и т.д.). Видеопроцессоры отличаются между собой архитектурой, поддерживающимися командами, наличием тех или иных вычислительных блоков, их количеством, быстродействием, размерами полупроводниковых элементов на кристалле GPU и т.д.;
Пример архитектуры видеочипа:
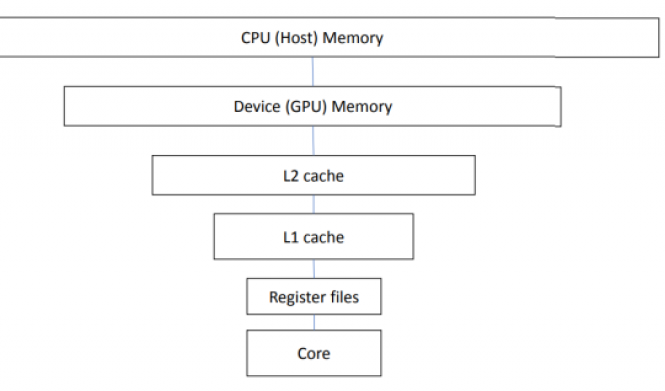
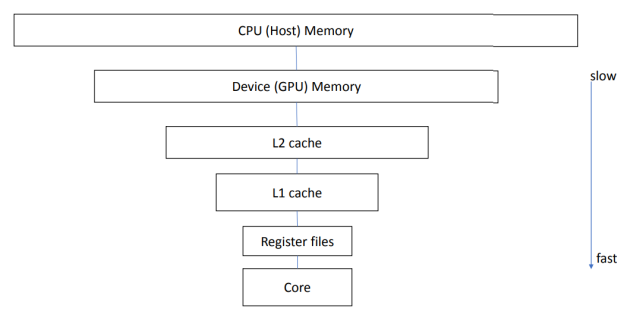
- видеопамять — предназначена для хранения данных, которые обрабатываются GPU, а также используются видеоконтроллером. В качестве памяти, использующейся для обработки данных видеокартой, могут использоваться различные компоненты, отличающиеся между собой быстродействием и объемом доступного пространства: системная память (ОЗУ), основная графическая память, кэш на кристалле видеопроцессора и регистры GPU;
Иерархическое представление уровней быстродействия памяти, использующейся при работе видеокарт:
- цифро-аналоговый преобразователь (RAMDAC, от англ. Random Access Memory Digital-to-Analog Converter) — предназначен для преобразования видеосигнала в соответствии со стандартом VGA. На современных видеокартах с выходами типа HDMI, DVI и т.д. не используется;
- кварцевый генератор — используется для формирования опорной частоты для синхронизации работы видеокарты с центральным процессором на материнской плате;
- микросхема BIOS, представляет собой постоянное запоминающее устройство, необходимое для инициализации видеокарты во время запуска. Содержит в себе микропрограмму, в которой указаны необходимые для работы вольтаж и частота памяти, видеопроцессора, алгоритм работы системы охлаждения и т.д.;
- подсистема питания — отвечает за формирование напряжений, необходимых для работы электронных компонентов видеокарты;
- система охлаждения — предназначена для отвода избыточного тепла, выделяющегося при работе электронных компонентов видеокарты и обеспечения оптимального температурного режима GPU, памяти и подсистемы питания.
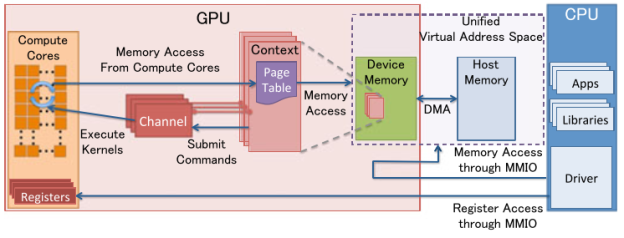
Полноценное функционирование видеокарты невозможно без видеодрайвера, который представляет собой интерфейс между операционной системой, видеоадаптером и выполняющимися на нем программами. Быстродействие видеокарты зависит не только от ее аппаратных возможностей (производительности вычислительных блоков GPU, частоты и объема памяти), но и от их практического использования с помощью драйверов.
Драйвер обеспечивает взаимодействие видеокарты и центрального процессора:
Плохо написанные драйвера могут существенно снизить производительность видеокарты. Например, на официальных драйверах видеокарты AMD Radeon R9 290/390 в Windows выдают на алгоритме Ethash порядка 20 mh/s, а в Linux — 30 mh/s (разница в производительности — 50%).
Для повышения производительности компьютерных вычислений в настоящее время используется обеспечение их одновременного параллельного выполнения на множестве ядер. Это связано с тем, что практический порог увеличения частоты работы одного ядра уже достигнут. Гнать частоту работы процессоров до определенного порога не имеет смысла, проще увеличить их количество. Кроме того, увеличить производительность можно с помощью добавления аппаратной поддержки выполнения сложной последовательности команд.
Для проведения сложных многопотоковых вычислений в современных видеокартах в большинстве случаев используются две технологии: стандарт OpenCL (Open Computing Language) и SDK CUDA (Compute Unified Device Architecture).
Выполнение многопотоковых вычислений с помощью технологии CUDA:
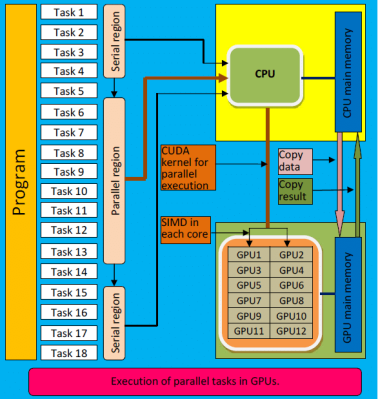
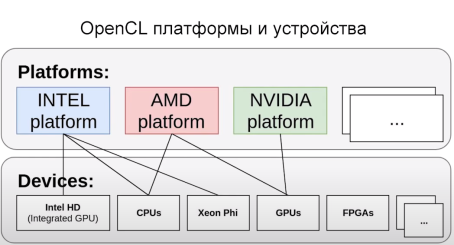
OpenCL — универсальная технология, может работать на множестве разных устройств, включая GPU, CPU, FPGA, интегрированные видеокарты, в то время как SDK CUDA используется только на видеокартах компании Nvidia.
ImageMagick и OpenCL
Поддержка OpenCL появилась в ImageMagick уже достаточно давно, однако по умолчанию она не активирована ни в одном дистрибутиве. Поэтому нам придется собрать IM самостоятельно из исходников. Ничего сложного в этом нет, все необходимое уже есть в SDK, поэтому сборка не потребует установки каких-то дополнительных библиотек от nVidia или AMD. Итак, скачиваем/распаковываем архив с исходниками:
$ wget http://goo.gl/F6VYV
$ tar -xjf ImageMagick-6.7.0-0.tar.bz2
$ cd ImageMagick-6.7.0-0
Далее устанавливаем инструменты сборки:
$ sudo apt-get install build-essential
Запускаем конфигуратор и грепаем его вывод на предмет поддержки OpenCL:
$ LDFLAGS=-L$LD_LIBRARY_PATH ./confi gure | grep -e cl.h -e OpenCL
Правильный результат работы команды должен выглядеть примерно так:
checking CL/cl.h usability... yes
checking CL/cl.h presence... yes
checking for CL/cl.h... yes
checking OpenCL/cl.h usability... no
checking OpenCL/cl.h presence... no
checking for OpenCL/cl.h... no
checking for OpenCL library... -lOpenCL
Словом "yes" должны быть отмечены либо первые три строки, либо вторые (или оба варианта сразу). Если это не так, значит, скорее всего, была неправильно инициализирована переменная C_INCLUDE_PATH. Если же словом "no" отмечена последняя строка, значит, дело в переменной LD_LIBRARY_PATH. Если все окей, запускаем процесс сборки/установки:
$ sudo make install clean
Проверяем, что ImageMagick действительно был скомпилирован с поддержкой OpenCL:
$ /usr/local/bin/convert -version | grep Features
Features: OpenMP OpenCL
Теперь измерим полученный выигрыш в скорости. Разработчики ImageMagick рекомендуют использовать для этого фильтр convolve:
$ time /usr/bin/convert image.jpg -convolve '-1, -1, -1, -1, 9, -1, -1, -1, -1' image2.jpg
$ time /usr/local/bin/convert image.jpg -convolve '-1, -1, -1, -1, 9, -1, -1, -1, -1' image2.jpg
Некоторые другие операции, такие как ресайз, теперь тоже должны работать значительно быстрее, однако надеяться на то, что ImageMagick начнет обрабатывать графику с бешеной скоростью, не стоит. Пока еще очень малая часть пакета оптимизирована с помощью OpenCL.
Ставим ATI Stream SDK
Stream SDK не требует установки, поэтому скачанный с сайта AMD-архив можно просто распаковать в любой каталог (лучшим выбором будет /opt) и прописать путь до него во всю ту же переменную LD_LIBRARY_PATH:
$ wget http://goo.gl/CNCNo
$ sudo tar -xzf ~/AMD-APP-SDK-v2.4-lnx64.tgz -C /opt
$ export LD_LIBRARY_PATH=/opt/AMD-APP-SDK-v2.4-lnx64/lib/x86_64/
$ export C_INCLUDE_PATH=/opt/AMD-APP-SDK-v2.4-lnx64/include/
Как и в случае с CUDA Toolkit, x86_64 необходимо заменить на x86 в 32-битных системах. Теперь переходим в корневой каталог и распаковываем архив icd-registration.tgz (это своего рода бесплатный лицензионный ключ):
$ sudo tar -xzf /opt/AMD-APP-SDK-v2.4-lnx64/icd-registration.tgz -С /
Проверяем правильность установки/работы пакета с помощью инструмента clinfo:
$ /opt/AMD-APP-SDK-v2.4-lnx64/bin/x86_64/clinfo
Они такие разные, CPU и GPU
Для полноценной работы вычислительной системы важны оба типа устройств. К примеру, мы выполняем пошаговую программу, некий последовательный алгоритм. Там нет возможности выполнить пятый шаг алгоритма, так данные для него рассчитываются на шаге четыре. В таком случае эффективнее использовать CPU с большим кэшем и высокой тактовой частотой. Но есть целые классы задач, хорошо поддающихся распараллеливанию. В таком случае эффективность GPU очевидна. Самый частый пример — вычисление пикселей отрендеренного изображения. Процедура для каждого пикселя почти одинаковая, данные о 3D объектах и текстурах находятся в ОЗУ видеокарты и каждый потоковый процессор может независимо от других посчитать свою часть изображения.Вот пример современной задачи — обучение нейронной сети. Большое количество одинаковых нейронов необходимо обучить, то есть поменять весовые коэффициенты каждого нейрона. После таких изменений нужно пропустить через нейросеть тестовые последовательности для обучения и получить вектора ошибок. Такие вычисления хорошо подходят для GPU. Каждый потоковый процессор может вести себя как нейрон и при вычислении не придется выстраивать решение последовательным образом, все наши вычисления будут происходить одновременно. Другой пример — расчет аэродинамических потоков. Необходимо выяснить возможное поведение проектируемого моста под воздействием ветра, смоделировать его аэродинамическую устойчивость, найти оптимальные места установки обтекателей для корректировки воздушных потоков или рассчитать устойчивость к ветровому резонансу. Помните знаменитый “танцующий мост” в Волгограде? Думаю, что никто не хотел бы оказаться в тот момент на мосту…
Поведение воздушного потока в каждой точке можно описать одинаковыми математическими уравнениями и решать эти уравнения параллельно на большом количестве ядер.
GPU — наше все?
Несмотря на все преимущества, техника GPGPU имеет несколько проблем. Первая из них заключается в очень узкой сфере применения. GPU шагнули далеко вперед центрального процессора в плане наращивания вычислительной мощности и общего количества ядер (видеокарты несут на себе вычислительный блок, состоящий из более чем сотни ядер), однако такая высокая плотность достигается за счет максимального упрощения дизайна самого чипа.
В сущности основная задача GPU сводится к математическим расчетам с помощью простых алгоритмов, получающих на вход не очень большие объемы предсказуемых данных. По этой причине ядра GPU имеют очень простой дизайн, мизерные объемы кэша и скромный набор инструкций, что в конечном счете и выливается в дешевизну их производства и возможность очень плотного размещения на чипе. GPU похожи на китайскую фабрику с тысячами рабочих. Какие-то простые вещи они делают достаточно хорошо (а главное — быстро и дешево), но если доверить им сборку самолета, то в результате получится максимум дельтаплан. Поэтому первое ограничение GPU — это ориентированность на быстрые математические расчеты, что ограничивает сферу применения графических процессоров помощью в работе мультимедийных приложений, а также любых программ, занимающихся сложной обработкой данных (например, архиваторов или систем шифрования, а также софтин, занимающихся флуоресцентной микроскопией, молекулярной динамикой, электростатикой и другими, малоинтересными для линуксоидов вещами).
Вторая проблема GPGPU в том, что адаптировать для выполнения на GPU можно далеко не каждый алгоритм. Отдельно взятые ядра графического процессора довольно медлительны, и их мощь проявляется только при работе сообща. А это значит, что алгоритм будет настолько эффективным, насколько эффективно его сможет распараллелить программист. В большинстве случаев с такой работой может справиться только хороший математик, которых среди разработчиков софта совсем немного.
И третье: графические процессоры работают с памятью, установленной на самой видеокарте, так что при каждом задействовании GPU будет происходить две дополнительных операции копирования: входные данные из оперативной памяти самого приложения и выходные данные из GRAM обратно в память приложения. Нетрудно догадаться, что это может свести на нет весь выигрыш во времени работы приложения (как и происходит в случае с инструментом FlacCL, который мы рассмотрим позже).
Но и это еще не все. Несмотря на существование общепризнанного стандарта в лице OpenCL, многие программисты до сих пор предпочитают использовать привязанные к производителю реализации техники GPGPU. Особенно популярной оказалась CUDA, которая хоть и дает более гибкий интерфейс программирования (кстати, OpenCL в драйверах nVidia реализован поверх CUDA), но намертво привязывает приложение к видеокартам одного производителя.
KGPU или ядро Linux, ускоренное GPU
Исследователи из университета Юты разработали систему KGPU, позволяющую выполнять некоторые функции ядра Linux на графическом процессоре с помощью фреймворка CUDA. Для выполнения этой задачи используется модифицированное ядро Linux и специальный демон, который работает в пространстве пользователя, слушает запросы ядра и передает их драйверу видеокарты с помощью библиотеки CUDA. Интересно, что несмотря на существенный оверхед, который создает такая архитектура, авторам KGPU удалось создать реализацию алгоритма AES, который поднимает скорость шифрования файловой системы eCryptfs в 6 раз.
Пример применения технологии
cRark
После того как мы узнали что такое параллельные вычисления и познакомились с технологией NVIDIA CUDA можно перейти к практической реализации данной технологии. Есть уж немало программного обеспечения, которое использует CUDA, но конкретно в этой статье мы будем рассматривать программу Павла Семянова под названием «cRark» Данная программа является одной из немногих программ на сегодняшний день, помогающих пользователям восстановить забытые пароли RAR-архивов, используя вычислительные способности графических процессоров с помощью технологии CUDA. Программа является бесплатной и свободной, что не ограничивает её применение в широких массах и позволяет пользователям более наглядно увидеть возможности CUDA. Саму программу cRark для различных операционных систем можно скачать с официального сайта, побольше узнать о авторе можно на сайте Павла Семянова.
Самое трудоёмкое в этой программе — это настойка. Программа имеет консольный интерфейс, но благодаря инструкции, которая прилагается к самой программе, ей можно пользоваться. Далее приведена краткая инструкция по настройке программы. Мы проверим программу на работоспособность и сравним её с другой подобной программой, которая не использует NVIDIA CUDA, в данном случае это известная программа «Advanced Archive Password Recovery».
Из скаченного архива cRark нам нужно только три файла: crark.exe, crark-hp.exe и password.def. Сrark.exe — это консольная утилита вскрытия паролей RAR 3.0 без шифрованных файлов внутри архива (т.е. раскрывая архив мы видим названия, но не можем распаковать архив без пароля).
Сrark-hp.exe — это консольная утилита вскрытия паролей RAR 3.0 с шифрованием всего архива (т.е. раскрывая архив мы не видим ни названия, ни самих архивов и не можем распаковать архив без пароля).
Password.def – это любой переименованный текстовой файл с очень небольшим содержанием (к примеру: 1-я строка: ## 2-я строка: ?*, в этом случае вскрытие пароля будет происходить с использованием всех знаков). Password.def — это руководитель програмы cRark. В файле содержаться правила вскрытия пароля (или область знаков которую crark.exe будет использовать в своей работе). Подробнее о возможностях выбора этих знаков написано в текстовом файле полученном при вскрытии скачанного на сайте у автора программы cRark: russian.def.
Подготовка
Сразу скажу, что программа работает только если ваша видеокарта основана на GPU с поддержкой уровня ускорения CUDA 1.1. Так что серия видеокарт, основанных на чипе G80, таких как GeForce 8800 GTX, отпадает, так как они имеют аппаратную поддержку ускорения CUDA 1.0. Программа подбирает с помощью CUDA только пароли на архивы RAR версий 3.0+. Необходимо установить все программное обеспечение, связанное с CUDA, а именно:
- Драйверы NVIDIA, поддерживающие CUDA, начиная с 169.21
- NVIDIA CUDA SDK, начиная с версии 1.1
- NVIDIA CUDA Toolkit, начиная с версии 1.1
Создаём любую папку в любом месте (например на диске С![]() и называем любым именем например «3.2». Помещаем туда файлы: crark.exe, crark-hp.exe и password.def и запароленный/зашифрованный архив RAR.
и называем любым именем например «3.2». Помещаем туда файлы: crark.exe, crark-hp.exe и password.def и запароленный/зашифрованный архив RAR.
Далее, следует запустить консоль командной строки Windows и перейти в ней созданную папку. В Windows Vista и 7 следует вызвать меню «Пуск» и в поле поиска ввести «cmd.exe», в Windows XP из меню «Пуск» сначала следует вызвать диалог «Выполнить» и уже в нём вводить «cmd.exe». После открытия консоли следует ввести команду вида: cd C:\папка\, cd C:\3.2 в данном случае.
Набираем в текстовом редакторе две строки (можно также сохранить текст как файл .bat в папке с cRark) для подбора пароля запароленного RAR-архива с незашифрованными файлами:
echo off;
cmd /K crark (название архива).rar
для подбора пароля запароленного и зашифрованного RAR-архива:
echo off;
cmd /K crark-hp (название архива).rar
Копируем 2 строки текстового файла в консоль и нажимаем Enter (или запускаем .bat файл).
Ставим CUDA Toolkit
Идем по вышеприведенной ссылке и скачиваем CUDA Toolkit для Linux (выбрать можно из нескольких версий, для дистрибутивов Fedora, RHEL, Ubuntu и SUSE, есть версии как для архитектуры x86, так и для x86_64). Кроме того, там же надо скачать комплекты драйверов для разработчиков (Developer Drivers for Linux, они идут первыми в списке).
Запускаем инсталлятор SDK:
$ sudo sh cudatoolkit_4.0.17_linux_64_ubuntu10.10.run
Когда установка будет завершена, приступаем к установке драйверов. Для этого завершаем работу X-сервера:
# sudo /etc/init.d/gdm stop
Открываем консоль$ sudo sh devdriver_4.0_linux_64_270.41.19.run
После окончания установки стартуем иксы:
$ startx
Чтобы приложения смогли работать с CUDA/OpenCL, прописываем путь до каталога с CUDA-библиотеками в переменную LD_LIBRARY_PATH:
$ export LD_LIBRARY_PATH=/usr/local/cuda/lib64
Или, если ты установил 32-битную версию:
$ export LD_LIBRARY_PATH=/usr/local/cuda/lib32
Также необходимо прописать путь до заголовочных файлов CUDA, чтобы компилятор их нашел на этапе сборки приложения:
$ export C_INCLUDE_PATH=/usr/local/cuda/include
Все, теперь можно приступить к сборке CUDA/OpenCL-софта.
Эволюция скорости
Если посмотреть прирост производительности в ходе решения задачи, то результаты были примерно такими:- полтора месяца до n=80 в Excel;
- час до n=80 на Core i5 с оптимизированной программой на С++;
- 10 минут до n=80 на Core i5 с использованием многопоточности;
- 10 минут до n=100 на одном GPU AMD RX 480;
- 120 минут до n=127 на ComBox A-480.
Что же такое вычисление на GPU
Вычисления на GPU — это использование GPU для вычисления технических, научных, бытовых задач. Вычисление на GPU заключает в себе использование CPU и GPU с разнородной выборкой между ними, а именно: последовательную часть программ берет на себя CPU, в то время как трудоёмкие вычислительные задачи остаются GPU. Благодаря этому происходит распараллеливание задач, которое приводит к ускорению обработки информации и уменьшает время выполнения работы, система становиться более производительной и может одновременно обрабатывать большее количество задач, чем ранее. Однако, чтобы добиться такого успеха одной лишь аппаратной поддержкой не обойтись, в данном случае необходима поддержка ещё и программного обеспечения, что бы приложение могло переносить наиболее трудоёмкие вычисления на GPU.
Программисты vs математики
Изначально математики решали эту задачу на Visual Basic в Excel, так удалось получить первичные решения, но невысокая производительность скриптовых языков не позволила продвинуться далеко вперед. Решение до n=80 заняло полтора месяца… Склоняем голову перед этими терпеливыми людьми.Первым этапом мы реализовали алгоритм задачи на языке Си и запустили на CPU. В процессе выяснилось, что при работе с битовыми последовательностями многое можно оптимизировать.
Далее мы оптимизировали область поиска и исключили дублирование. Также хороший результат дал анализ генерируемого компилятором ассемблерного кода и оптимизация кода под особенности компилятора. Всё это позволило добиться существенного прироста скорости вычислений.
Следующим этапом оптимизации стало профилирование. Замер времени выполнения различных участков кода показал, что в некоторых ветках алгоритма сильно возрастала нагрузка на память, а также выявилось излишнее ветвление программы. Из-за этого “маленького” недочёта почти треть мощности CPU была не задействована.
Очень важным аспектом решения подобных задач является аккуратность написания кода. Правильных ответов на эту задачу никто не знает и тестовых векторов соответственно нет. Есть лишь первая часть диапазона решений, которые были найдены математиками. Достоверность новых решений можно гарантировать только аккуратностью написания кода.
Вот и наступил этап подготовки программы для решения на GPU и код был модифицирован для работы в несколько потоков. Управляющая программа теперь занималась диспетчеризацией задач между потоками. В многопоточной среде скорость вычисления увеличилась в 5 раз! Этого удалось добиться за счет одновременной работы 4 потоков и объединения функций.
На этом этапе решение производило верные расчеты до n=80 за 10 минут, тогда как в Exсel’e эти расчеты занимали полтора месяца! Маленькая победа!
ComBox A-480 GPU или один миллион ядер
0
Источник:
Эта самая интересная часть проекта, когда от Excel мы перешли на вычислительный кластер состоящий из 480 видеокарт AMD RX 480. Большого, быстрого, эффективного. Полностью готового к выполнению поставленной задачи и получению тех результатов, которых мир еще никогда не видел.Хочется отметить что на всех этапах совершенствования и оптимизации кода мы запускали поиск решения с самого начала и сравнивали ответы новой версии с предыдущими. Это позволяло быть уверенными, что оптимизация кода и доработки не вносят ошибки в решения. Тут нужно понимать, что правильных ответов в конце учебника нет, и никто в мире их не знает.
Запуск на кластере подтвердил наши предположения по скорости решений: поиск последовательностей для n>100 занимал около часа. Было удивительно видеть как на кластере ComBox A-480 новые решения находились за минуты, в то время как на CPU это занимало многие часы.
Всего через два часа работы вычислительного кластера мы получили все решения до n=127. Проверка решений показала, что полученные ответы достоверны и соответствуют изложенным в статье теоремам профессора Чуднова А.М.
Конфигурация стенда для тестирования
Стенд для тестирования имел следующую конфигурацию:
- процессор — Intel Core i7-3770K;
- материнская плата — Gigabyte GA-Z77X-UD5H;
- чипсет системной платы — Intel Z77 Express;
- память — DDR3-1600;
- объем памяти — 8 Гбайт (два модуля GEIL по 4 Гбайт);
- режим работы памяти — двухканальный;
- видеокарта — NVIDIA GeForce GTX 660Ti (видеодрайвер 314.07);
- накопитель — Intel SSD 520 (240 Гбайт).
На стенде устанавливалась операционная система Windows 7 Ultimate (64-bit).
Первоначально мы провели тестирование в штатном режиме работы процессора и всех остальных компонентов системы. При этом процессор Intel Core i7-3770K работал на штатной частоте 3,5 ГГц c активированным режимом Turbo Boost (максимальная частота процессора в режиме Turbo Boost составляет 3,9 ГГц).
Затем мы повторили процесс тестирования, но при разгоне процессора до фиксированной частоты 4,5 ГГц (без использования режима Turbo Boost). Это позволило выявить зависимость скорости конвертирования от частоты процессора (CPU).
На следующем этапе тестирования мы вернулись к штатным настройкам процессора и повторили тестирование уже с другими видеокартами:
- NVIDIA GeForce GTX 280 (драйвер 314.07);
- NVIDIA GeForce GTX 460 (драйвер 314.07);
- AMD Radeon HD6850 (драйвер 13.1).
Таким образом, видеоконвертирование проводилось на четырех видеокартах различной архитектуры.
Старшая видеокарта NVIDIA GeForce 660Ti основана на одноименном графическом процессоре с кодовым обозначением GK104 (архитектура Kepler), производимом по 28-нм техпроцессу. Этот графический процессор содержит 3,54 млрд транзисторов, а площадь кристалла составляет 294 мм2.
Напомним, что графический процессор GK104 включает четыре кластера графической обработки (Graphics Processing Clusters, GPC). Кластеры GPC являются независимыми устройствами в составе процессора и способны работать как отдельные устройства, поскольку обладают всеми необходимыми ресурсами: растеризаторами, геометрическими движками и текстурными модулями.
Каждый такой кластер имеет два потоковых мультипроцессора SMX (Streaming Multiprocessor), но в процессоре GK104 в одном из кластеров один мультипроцессор заблокирован, поэтому всего имеется семь мультипроцессоров SMX.
Каждый потоковый мультипроцессор SMX содержит 192 потоковых вычислительных ядра (ядра CUDA), поэтому в совокупности процессор GK104 насчитывает 1344 вычислительных ядра CUDA. Кроме того, каждый SMX-мультипроцессор содержит 16 текстурных модулей (TMU), 32 блока специальных функций (Special Function Units, SFU), 32 блока загрузки и хранения (Load-Store Unit, LSU), движок PolyMorph и многое другое.
Видеокарта GeForce GTX 460 основана на графическом процессоре с кодовым обозначением GF104 на базе архитектуры Fermi. Этот процессор производится по 40-нм техпроцессу и содержит порядка 1,95 млрд транзисторов.
Графический процессор GF104 включает два кластера графической обработки GPC. Каждый из них имеет четыре потоковых мультипроцессора SM, но в процессоре GF104 в одном из кластеров один мультипроцессор заблокирован, поэтому существует всего семь мультипроцессоров SM.
Каждый потоковый мультипроцессор SM содержит 48 потоковых вычислительных ядра (ядра CUDA), поэтому в совокупности процессор GK104 насчитывает 336 вычислительных ядра CUDA. Кроме того, каждый SM-мультипроцессор содержит восемь текстурных модулей (TMU), восемь блоков специальных функций (Special Function Units, SFU), 16 блоков загрузки и хранения (Load-Store Unit, LSU), движок PolyMorph и многое другое.
Графический процессор GeForce GTX 280 относится ко второму поколению унифицированной архитектуры графических процессоров NVIDIA и по своей архитектуре сильно отличается от архитектуры Fermi и Kepler.
Графический процессор GeForce GTX 280 состоит из кластеров обработки текстур (Texture Processing Clusters, TPC), которые, хоть и похожи, но в то же время сильно отличаются от кластеров графической обработки GPC в архитектурах Fermi и Kepler. Всего таких кластеров в процессоре GeForce GTX 280 насчитывается десять. Каждый TPC-кластер включает три потоковых мультипроцессора SM и восемь блоков текстурной выборки и фильтрации (TMU). Каждый мультипроцессор состоит из восьми потоковых процессоров (SP). Мультипроцессоры также содержат блоки выборки и фильтрации текстурных данных, используемых как в графических, так и в некоторых расчетных задачах.
Таким образом, в одном TPC-кластере — 24 потоковых процессора, а в графическом процессоре GeForce GTX 280 их уже 240.
Сводные характеристики используемых в тестировании видеокарт на графических процессорах NVIDIA представлены в таблице.
В приведенной таблице нет видеокарты AMD Radeon HD6850, что вполне естественно, поскольку по техническим характеристикам ее трудно сравнивать с видеокартами NVIDIA. А потому рассмотрим ее отдельно.
Графический процессор AMD Radeon HD6850, имеющий кодовое наименование Barts, изготовляется по 40-нм техпроцессу и содержит 1,7 млрд транзисторов.
Архитектура процессора AMD Radeon HD6850 представляет собой унифицированную архитектуру с массивом общих процессоров для потоковой обработки многочисленных видов данных.
Процессор AMD Radeon HD6850 состоит из 12 SIMD-ядер, каждое из которых содержит по 16 блоков суперскалярных потоковых процессоров и четыре текстурных блока. Каждый суперскалярный потоковый процессор содержит пять универсальных потоковых процессоров. Таким образом, всего в графическом процессоре AMD Radeon HD6850 насчитывается 12*um*16*um*5=960 универсальных потоковых процессоров.
Частота графического процессора видеокарты AMD Radeon HD6850 составляет 775 МГц, а эффективная частота памяти GDDR5 — 4000 МГц. При этом объем памяти составляет 1024 Мбайт.
Преимущества технологии
- Интерфейс программирования приложений CUDA (CUDAAPI) основан на стандартном языке программирования Си с некоторыми ограничениями. Это упрощает и сглаживает процеcс изучения архитектуры CUDA.
- Разделяемая между потоками память (shared memory) размером в 16 Кб может быть использована под организованный пользователем кэш с более широкой полосой пропускания, чем при выборке из обычных текстур.
- Более эффективные транзакции между памятью центрального процессора и видеопамятью.
- Полная аппаратная поддержка целочисленных и побитовых операций.
NVIDIA CUDA и AMD APP
Именно поэтому, когда стали предприниматься первые попытки реализовать неграфические вычисления на GPU (General Purpose GPU, GPGPU), возник компилятор BrookGPU. До его создания разработчикам приходилось получать доступ к ресурсам видеокарты через графические API OpenGL или Direct3D, что значительно усложняло процесс программирования, так как требовало специфических знаний — приходилось изучать принципы работы с 3D-объектами (шейдерами, текстурами и т.п.). Это явилось причиной весьма ограниченного применения GPGPU в программных продуктах. BrookGPU стал своеобразным «переводчиком». Эти потоковые расширения к языку Си скрывали от программистов трехмерный API и при его использовании надобность в знаниях 3D-программирования практически отпала. Вычислительные мощности видеокарт стали доступны программистам в виде дополнительного сопроцессора для параллельных расчетов. Компилятор BrookGPU обрабатывал файл с кодом Cи и расширениями, выстраивая код, привязанный к библиотеке с поддержкой DirectX или OpenGL.
Во многом благодаря BrookGPU, компании NVIDIA и ATI (ныне AMD) обратили внимание на зарождающуюся технологию вычислений общего назначения на графических процессорах и начали разработку собственных реализаций, обеспечивающих прямой и более прозрачный доступ к вычислительным блокам 3D-ускорителей.
В результате компания NVIDIA разработала программно-аппаратную архитектуру параллельных вычислений CUDA (Compute Unified Device Architecture). Архитектура CUDA позволяет реализовать неграфические вычисления на графических процессорах NVIDIA.
Релиз публичной бета-версии CUDA SDK состоялся в феврале 2007 года. В основе API CUDA лежит упрощенный диалект языка Си. Архитектура CUDA SDK обеспечивает программистам реализацию алгоритмов, выполнимых на графических процессорах NVIDIA, и включение специальных функций в текст программы на Cи. Для успешной трансляции кода на этом языке в состав CUDA SDK входит собственный Сикомпилятор командной строки nvcc компании NVIDIA.
CUDA — это кроссплатформенное программное обеспечение для таких операционных систем, как Linux, Mac OS X и Windows.
Компания AMD (ATI) также разработала свою версию технологии GPGPU, которая ранее называлась AТI Stream, а теперь — AMD Accelerated Parallel Processing (APP). Основу AMD APP составляет открытый индустриальный стандарт OpenCL (Open Computing Language). Стандарт OpenCL обеспечивает параллелизм на уровне инструкций и на уровне данных и является реализацией техники GPGPU. Это полностью открытый стандарт, его использование не облагается лицензионными отчислениями. Отметим, что AMD APP и NVIDIA CUDA несовместимы друг с другом, тем не менее, последняя версия NVIDIA CUDA поддерживает и OpenCL.
Тестирование GPGPU в видеоконвертерах
Итак, мы выяснили, что для реализации GPGPU на графических процессорах NVIDIA предназначена технология CUDA, а на графических процессорах AMD — API APP. Как уже отмечалось, использование неграфических вычислений на GPU целесообразно только в том случае, если решаемая задача может быть распараллелена на множество потоков. Однако большинство пользовательских приложений не удовлетворяют этому критерию. Впрочем, есть и некоторые исключения. К примеру, большинство современных видеоконвертеров поддерживают возможность использования вычислений на графических процессорах NVIDIA и AMD.
Для того чтобы выяснить, насколько эффективно используются вычисления на GPU в пользовательских видеоконвертерах, мы отобрали три популярных решения: Xilisoft Video Converter Ultimate 7.7.2, Wondershare Video Converter Ultimate 6.0.3.2 и Movavi Video Converter 10.2.1. Эти конвертеры поддерживают возможность использования графических процессоров NVIDIA и AMD, причем в настройках видеоконвертеров можно отключить эту возможность, что позволяет оценить эффективность применения GPU.
Для видеоконвертирования мы применяли три различных видеоролика.
Первый видеоролик имел длительность 3 мин 35 с и размер 1,05 Гбайт. Он был записан в формате хранения данных (контейнер) mkv и имел следующие характеристики:
- видео:
- формат — MPEG4 Video (H264),
- разрешение — 1920*um*1080,
- режим битрейта — Variable,
- средний видеобитрейт — 42,1 Мбит/с,
- максимальный видеобитрейт — 59,1 Мбит/с,
- частота кадров — 25 fps;
- аудио:
- формат — MPEG-1 Audio,
- аудиобитрейт — 128 Кбит/с,
- количество каналов — 2,
- частота семплирования — 44,1 кГц.
Второй видеоролик имел длительность 4 мин 25 с и размер 1,98 Гбайт. Он был записан в формате хранения данных (контейнер) MPG и имел следующие характеристики:
- видео:
- формат — MPEG-PS (MPEG2 Video),
- разрешение — 1920*um*1080,
- режим битрейта — Variable.
- средний видеобитрейт — 62,5 Мбит/с,
- максимальный видеобитрейт — 100 Мбит/с,
- частота кадров — 25 fps;
- аудио:
- формат — MPEG-1 Audio,
- аудиобитрейт — 384 Кбит/с,
- количество каналов — 2,
- частота семплирования — 48 кГц.
Третий видеоролик имел длительность 3 мин 47 с и размер 197 Мбайт. Он был записан в формате хранения данных (контейнер) MOV и имел следующие характеристики:
- видео:
- формат — MPEG4 Video (H264),
- разрешение — 1920*um*1080,
- режим битрейта — Variable,
- видеобитрейт — 7024 Кбит/с,
- частота кадров — 25 fps;
- аудио:
- формат — AAC,
- аудиобитрейт — 256 Кбит/с,
- количество каналов — 2,
- частота семплирования — 48 кГц.
Все три тестовых видеоролика конвертировались с использованием видеоконвертеров в формат хранения данных MP4 (кодек H.264) для просмотра на планшете iPad 2. Разрешение выходного видеофайла составляло 1280*um*720.
Отметим, что мы не стали использовать абсолютно одинаковые настройки конвертирования во всех трех конвертерах. Именно поэтому по времени конвертирования некорректно сравнивать эффективность самих видеоконвертеров. Так, в видеоконвертере Xilisoft Video Converter Ultimate 7.7.2 для конвертирования применялся пресет iPad 2 — H.264 HD Video. В этом пресете используются следующие настройки кодирования:
- кодек — MPEG4 (H.264);
- разрешение — 1280*um*720;
- частота кадров — 29,97 fps;
- видеобитрейт — 5210 Кбит/с;
- аудиокодек — AAC;
- аудиобитрейт — 128 Кбит/с;
- количество каналов — 2;
- частота семплирования — 48 кГц.
В видеоконвертере Wondershare Video Converter Ultimate 6.0.3.2 использовался пресет iPad 2 cо следующими дополнительными настройками:
- кодек — MPEG4 (H.264);
- разрешение — 1280*um*720;
- частота кадров — 30 fps;
- видеобитрейт — 5000 Кбит/с;
- аудиокодек — AAC;
- аудиобитрейт — 128 Кбит/с;
- количество каналов — 2;
- частота семплирования — 48 кГц.
В конвертере Movavi Video Converter 10.2.1 применялся пресет iPad (1280*um*720, H.264) (*.mp4) со следующими дополнительными настройками:
- видеоформат — H.264;
- разрешение — 1280*um*720;
- частота кадров — 30 fps;
- видеобитрейт — 2500 Кбит/с;
- аудиокодек — AAC;
- аудиобитрейт — 128 Кбит/с;
- количество каналов — 2;
- частота семплирования — 44,1 кГц.
Конвертирование каждого исходного видеоролика проводилось по пять раз на каждом из видеоконвертеров, причем с использованием как графического процессора, так и только CPU. После каждого конвертирования компьютер перезагружался.
В итоге, каждый видеоролик конвертировался десять раз в каждом видеоконвертере. Для автоматизации этой рутинной работы была написана специальная утилита с графическим интерфейсом, позволяющая полностью автоматизировать процесс тестирования.

























